Utility functions¶
scrapple.utils.dynamicdispatch¶
Functions related to dynamic dispatch of objects
-
scrapple.utils.dynamicdispatch.get_command_class(command)[source]¶ Called from runCLI() to select the command class for the selected command.
Parameters: command – The command to be implemented Returns: The command class corresponding to the selected command
This function is implemented through this simple code block :
from scrapple.commands import genconfig, generate, run, web
cmdClass = getattr(eval(command), command.title() + 'Command')
return cmdClass
scrapple.utils.exceptions¶
Functions related to handling exceptions in the input arguments
The function uses regular expressions to validate the CLI input.
projectname_re = re.compile(r'[^a-zA-Z0-9_]')
if args['genconfig']:
if args['--type'] not in ['scraper', 'crawler']:
raise Exception("--type has to be 'scraper' or 'crawler'")
if args['--selector'] not in ['xpath', 'css']:
raise Exception("--selector has to be 'xpath' or 'css'")
if args['generate'] or args['run']:
if args['--output_type'] not in ['json', 'csv']:
raise Exception("--output_type has to be 'json' or 'csv'")
if args['genconfig'] or args['generate'] or args['run']:
if projectname_re.search(args['<projectname>']) is not None:
raise Exception("Invalid <projectname>")
return
scrapple.utils.config¶
Functions related to traversing the configuration file
-
scrapple.utils.config.traverse_next(page, nextx, results, tabular_data_headers=[], verbosity=0)[source]¶ Recursive generator to traverse through the next attribute and crawl through the links to be followed.
Parameters: - page – The current page being parsed
- next – The next attribute of the current scraping dict
- results – The current extracted content, stored in a dict
Returns: The extracted content, through a generator
In the case of crawlers, the configuration file can be treated as a tree, with the anchor tag links extracted from the follow link selector as the child nodes. This level-wise representation of the crawler configuration file provides a clear picture of how the file should be parsed.
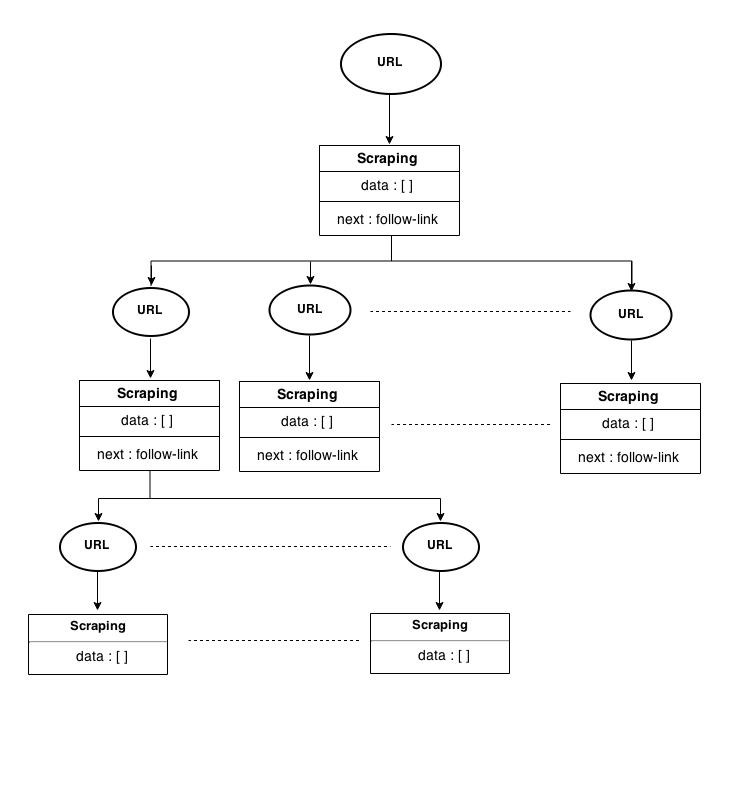
Tree representation of crawler
This recursive generator performs a depth-first traversal of the config file tree. It can be implemented through this code snippet :
for link in page.extract_links(next['follow_link']):
r = results.copy()
for attribute in next['scraping'].get('data'):
if attribute['field'] != "":
r[attribute['field']] = \
link.extract_content(attribute['selector'],
attribute['attr'],
attribute['default'])
if not next['scraping'].get('next'):
yield r
else:
for next2 in next['scraping'].get('next'):
for result in traverse_next(link, next2, r):
yield result
-
scrapple.utils.config.get_fields(config)[source]¶ Recursive generator that yields the field names in the config file
Parameters: config – The configuration file that contains the specification of the extractor Returns: The field names in the config file, through a generator
get_fields() parses the configuration file through a recursive generator, yielding the field names encountered.
for data in config['scraping']['data']:
if data['field'] != '':
yield data['field']
if 'next' in config['scraping']:
for n in config['scraping']['next']:
for f in get_fields(n):
yield f
-
scrapple.utils.config.extract_fieldnames(config)[source]¶ Function to return a list of unique field names from the config file
Parameters: config – The configuration file that contains the specification of the extractor Returns: A list of field names from the config file
The extract_fieldnames() function uses the get_fields() generator, and handles cases like multiple occurrences of the same field name.
fields = []
for x in get_fields(config):
if x in fields:
fields.append(x + '_' + str(fields.count(x) + 1))
else:
fields.append(x)
return fields
scrapple.utils.form¶
Functions related to form handling.
-
scrapple.utils.form.form_to_json(form)[source]¶ Takes the form from the POST request in the web interface, and generates the JSON config file
Parameters: form – The form from the POST request Returns: None
The web form is structured in a way that all the data field are linearly numbered. This is done so that it is easier to process the form while converting it into a JSON document.
for i in itertools.count(start=1):
try:
data = {
'field': form['field_' + str(i)],
'selector': form['selector_' + str(i)],
'attr': form['attribute_' + str(i)],
'default': form['default_' + str(i)]
}
config['scraping']['data'].append(data)
except KeyError:
break